Azure OpenAI
Az Azure OpenAI Service hozzáférést biztosít fejlett nyelvi modellekhez, amelyeket testreszabhat beszélgetésalapú mesterséges intelligenciához, tartalomkészítéshez és adatalapú megoldásokhoz.
Beállítás előtt
A kapcsolat létrehozása előtt győződjön meg arról, hogy:
- Rendelkezik az Azure OpenAI fiókjához tartozó
Resource URLcímmel. - Ismeri az Azure OpenAI fiókjához tartozó
Deployment nameésAPI keyadatokat.
Az Azure OpenAI Service erőforrás létrehozásáról és telepítéséről itt talál információkat.
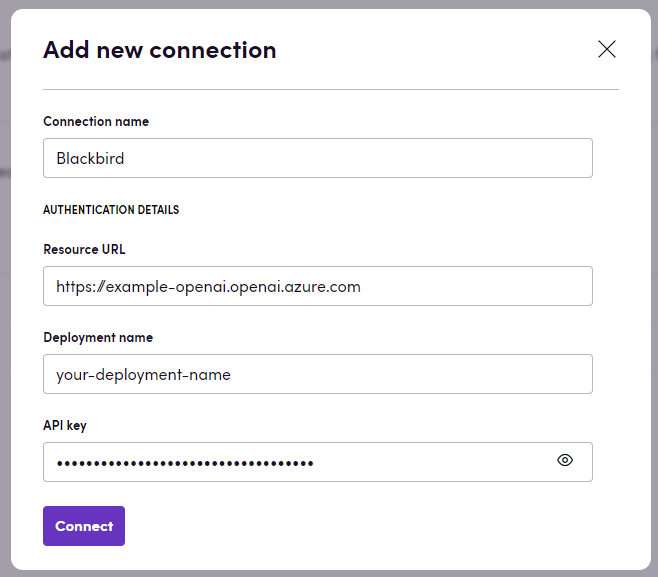
Csatlakozás
- Navigáljon az Alkalmazásokhoz, és keresse meg az Azure OpenAI alkalmazást. A keresést használhatja a megtalálásához.
- Kattintson az Add Connection gombra.
- Nevezze el a kapcsolatot a későbbi hivatkozáshoz, például ‘Saját Azure OpenAI kapcsolat’.
- Adja meg az Azure OpenAI fiókjához tartozó
Resource URL,Deployment nameésAPI keyadatokat. - Kattintson a Connect gombra.
- Ellenőrizze, hogy a kapcsolat sikeresen létrejött.
MEGJEGYZÉS: Figyeljen a
Resource URLkapcsolati paraméterre. Néha a helyes URL-nek lehet valamilyen útvonala a domain név után. Például: https://example.openai.azure.com/**openai**
Actions
Chat actions
- Generate completion: Kiegészíti a megadott promptot.
- Chat: Választ ad egy chat üzenetre.
- Chat with system prompt: Választ ad egy chat üzenetre és egy konfigurálható rendszer promptra.
- Create summary: Összefoglalja a bevitt szöveget.
- Generate edit: Szerkeszti a bevitt szöveget egy utasítás prompt alapján.
- Execute Blackbird prompt: Végrehajtja a Blackbird AI eszközei által generált promptot.
Translation-Related Actions
- Post-edit MT: Felülvizsgálja a gépi fordítású szöveget és létrehoz egy utószerkesztett verziót.
- Get translation issues: Felülvizsgálja a szövegfordítást és létrehoz egy megjegyzést a problémák leírásával.
- Get MQM report: Elvégzi a fordítás LQA elemzését. Az eredmény MQM keretrendszer formájában lesz.
- Get MQM dimension values: Elvégzi a fordítás LQA elemzését. Ez a művelet csak az egyes dimenziók pontszámait (1 és 10 között) adja vissza.
- Translate text: Lokalizálja a megadott szöveget.
Audio Actions
- Create English translation: Angol fordítást készít egy hang- vagy videofájl alapján (mp3, mp4, mpeg, mpga, m4a, wav vagy webm).
- Create transcription: Átírást készít egy hang- vagy videofájl alapján (mp3, mp4, mpeg, mpga, m4a, wav vagy webm).
Image Actions
- Generate image: Képet generál egy prompt alapján.
Text Analysis Actions
- Create embedding: Beágyazást generál a megadott szöveghez. A beágyazás lebegőpontos számok listája, amely rögzíti az általa reprezentált szöveg szemantikai információit.
- Tokenize text: Tokenizálja a megadott szöveget. Opcionálisan megadhatja a kódolást: cl100k_base (a gpt-4, gpt-3.5-turbo, text-embedding-ada-002 által használt) vagy p50k_base (a codex modellek, text-davinci-002, text-davinci-003 által használt).
XLIFF Actions
Fontos, hogy jelenleg csak a gpt-4o 2024-08-06-os verziója támogatja a strukturált kimeneteket. Ez azt jelenti, hogy az XLIFF fájlokat támogató műveletek csak ezzel a modellverzióval használhatók. A támogatott modellekről további információkat az Azure OpenAI dokumentációban találhat.
-
Get Quality Scores for XLIFF file Szegmens és fájl szintű minőségi pontszámokat ad az XLIFF fájlokhoz. Jelenleg csak az XLIFF 1.2-es verzióját támogatja. Opcionálisan hozzáadhatja a Threshold, New Target State és Condition bemeneti paramétereket a Blackbird művelethez, hogy módosítsa a kívánt kritériumoknak megfelelő szegmensek célállapot-értékét (mindháromnak kitöltöttnek kell lennie).
Opcionális bemenetek:
- Prompt: Adja meg a forrás-cél párok értékelésének kritériumait. Ha nem ad meg semmit, ezt helyettesíti a “accuracy, fluency, consistency, style, grammar and spelling”.
- Bucket size: Az ugyanabban a kérésben feldolgozandó fordítási egységek mennyisége. (Lásd a dedikált szakaszt)
- Source and Target languages: Alapértelmezés szerint ezeket az értékeket az XLIFF fejlécből vesszük. Megadhat más értékeket is, nincs szükség speciális formátumra.
- Threshold: 0-10 közötti érték.
- Condition: Kritériumok azon szegmensek szűréséhez, amelyek célállapota módosulni fog.
- New Target State: érték a szűrt fordítási egységek célállapotának frissítéséhez.
Kimenet:
- Average Score: az összes szegmensszintű pontszám összesített értéke.
- Updated XLIFF file: szegmensszintű pontszám hozzáadva az extradata attribútumhoz és frissített célállapot, ha kérve lett.
-
Post-edit XLIFF file Frissíti az XLIFF 1.2 fájlok célelemeit
Opcionális bemenetek:
- Prompt: Adja meg a célszövegek utószerkesztésének nyelvi kritériumait.
- Bucket size: Az ugyanabban a kérésben feldolgozandó fordítási egységek mennyisége. (Lásd a dedikált szakaszt)
- Source and Target languages: Alapértelmezés szerint ezeket az értékeket az XLIFF fejlécből vesszük. Megadhat más értékeket is, nincs szükség speciális formátumra.
- Glossary
-
Process XLIFF file Egy XLIFF fájl esetén feldolgozza az egyes fordítási egységeket a megadott utasítások szerint (alapértelmezés szerint a forráscímkék fordítása), és frissíti az egyes egységek célszövegét. Ez a művelet jelenleg csak az XLIFF 1.2-es verzióját támogatja.
Bucket size, teljesítmény és költség
Az XLIFF fájlok sok szegmenst tartalmazhatnak. Minden művelet feldolgozza a szegmenseket és elküldi őket az AI alkalmazásnak. Előfordulhat, hogy a szegmensek száma olyan magas, hogy a prompt meghaladja a modell kontextusablakát, vagy a modell hosszabb ideig fut, mint amennyit a Blackbird műveletek megengednek. Ezért vezettük be a bucket size paramétert. A bucket size paraméter beállításával meghatározhatja, hogy egyszerre hány szegmenst küldjön az AI modellnek. Ez lehetővé teszi a munkaterhelés felosztását különböző API-hívásokra. A hátrány az, hogy ugyanazt a kontextus promptot minden kéréssel el kell küldeni (ami növeli a felhasznált tokenek számát). Kísérleteink alapján a gpt-4o-hoz hasonló modellek esetében az 1500-as bucket size elegendő. Ezért az alapértelmezett bucket size 1500, azonban más modellek eltérő értékeket igényelhetnek.
Kötegelt feldolgozás
Használhatja a kötegelt (aszinkron) műveleteket nagyméretű XLIFF fájlok feldolgozásához. A kötegelt művelet egy batch objektumot ad vissza, amelyet használhat a feldolgozás állapotának ellenőrzéséhez a Batch ID segítségével. Vegye figyelembe, hogy a modellt Global-batch-ként kell telepíteni. A modell Global-batch-ként történő telepítéséről további információkat az Azure OpenAI dokumentációban találhat.
A Deployment name-et (a kapcsolatból) modellként fogjuk használni, ezért győződjön meg arról, hogy a modell Global-batch-ként van telepítve, és a kapcsolatban a megfelelő telepítési nevet adta meg. A telepítési név példája: organization-gpt-4o-globalbatch.
- (Batch) Process XLIFF file - Aszinkron módon feldolgozza az XLIFF fájl minden fordítási egységét a megadott utasítások szerint (alapértelmezés szerint csak a forráscímkéket fordítja le), és frissíti minden egység célszövegét.
- (Batch) Post-edit XLIFF file - Aszinkron módon utószerkeszti az XLIFF fájl minden fordítási egységének célszövegét a megadott utasítások szerint, és frissíti minden egység célszövegét.
- (Batch) Get Quality Scores for XLIFF file - Aszinkron módon minőségi pontszámokat kap az XLIFF fájl minden fordítási egységéhez.
A kötegelt feldolgozás eredményeinek lekéréséhez használhatja a következő műveleteket:
- (Batch) Get results of the batch process - Lekéri a kötegelt folyamat eredményeit. Ez a művelet csak az XLIFF fájl feldolgozására és utószerkesztésére alkalmas, és a kötegelt folyamat befejezése után kell meghívni.
- (Batch) Get quality scores results - Lekéri a kötegelt folyamat minőségi pontszámait. Ez a művelet csak az XLIFF fájl minőségi pontszámainak lekérésére alkalmas, és a kötegelt folyamat befejezése után kell meghívni.
Fontos, hogy az Original XLIFF bemenetben a megfelelő eredeti XLIFF fájlt kell megadni. Ez segít nekünk a frissített célszegmensekkel rendelkező helyes XLIFF fájl létrehozásában.
Példa
Íme egy példa arra, hogyan használhatja az Azure OpenAI alkalmazást egy munkafolyamatban:
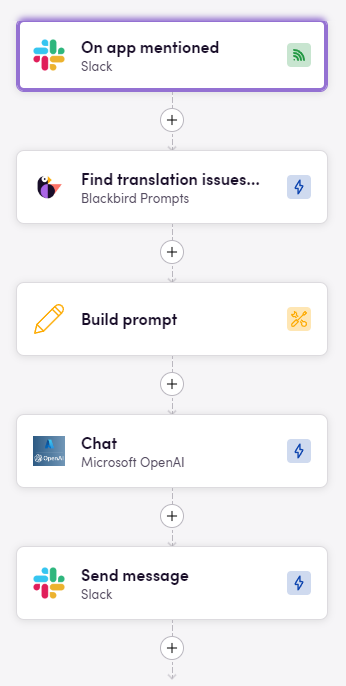
Ez a munkafolyamat automatizálja egy specifikus Slack-trigger kezelését. Íme a lépésről lépésre történő lebontás:
- On app mentioned (Slack): A munkafolyamat akkor indul, amikor az alkalmazást megemlítik egy Slack-csatornán.
- Find translation issues (Blackbird Prompts): Ezután a Blackbird Prompts segítségével megkeresi a fordítási problémákat a megemlített tartalomban.
- Build prompt: Ezt követően létrehoz egy promptot az azonosított problémák alapján.
- Chat (Azure OpenAI): A létrehozott promptot elküldi az Azure OpenAI-nak, hogy választ vagy megoldást generáljon.
- Send message (Slack): Végül az OpenAI-tól kapott választ üzenetként visszaküldi a Slack-csatornán.
Visszajelzés
Szeretné használni ezt az alkalmazást, vagy visszajelzése van a megvalósításunkkal kapcsolatban? Keressen meg bennünket a megszokott csatornákon keresztül, vagy hozzon létre egy problémát.