Google Vertex AI
A Vertex AI egy átfogó platform, amely hozzáférést biztosít olyan erőteljes multimodális modellekhez, mint a Google Gemini, lehetővé téve a fejlesztők számára, hogy zökkenőmentesen kombinálják a különböző bemeneteket, mint szöveg, kép, videó vagy kód. A modellek széles választékával a Vertex AI megkönnyíti a testreszabást és integrációt, lehetővé téve az AI alkalmazások fejlesztését és telepítését. A platform generatív AI modelleket, teljesen menedzselt eszközöket és célzott MLOps megoldásokat kínál a gépi tanulási életciklus teljes körű kezeléséhez — a betanítástól és finomhangolástól kezdve a telepítésig és monitorozásig.
Beállítás előtt
A kapcsolódás előtt győződjön meg a következőkről:
- Kiválasztott vagy létrehozott egy Cloud Platform projektet.
- Engedélyezte a számlázást a projekthez.
- Engedélyezte a Vertex AI API-t.
- Létrehozott egy szolgáltatási fiókot és generált JSON kulcsokat.
Szolgáltatási fiók létrehozása és JSON kulcsok generálása
- Navigáljon a kiválasztott vagy létrehozott Cloud Platform projekthez.
- Menjen az IAM & Admin részhez.
- A bal oldali menüben válassza a Service accounts opciót.
- Kattintson a Create service account gombra.
- Adjon meg egy szolgáltatásifiók-nevet és opcionálisan egy leírást. Kattintson a Create and continue gombra. Válassza a Vertex AI Administrator vagy Vertex AI User szerepkört a szolgáltatási fiókhoz és kattintson a Continue gombra.
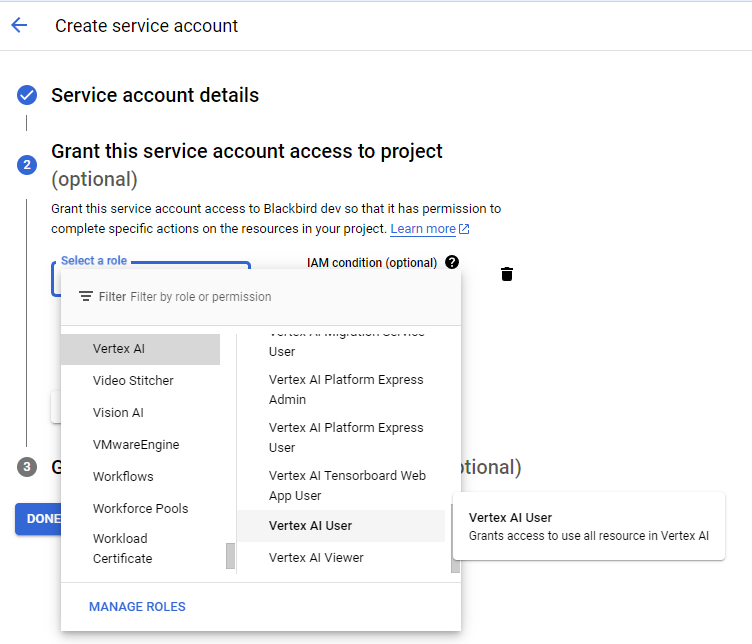
- Kattintson a Done gombra.
- A szolgáltatási fiókok listájából válassza ki az újonnan létrehozott szolgáltatási fiókot és navigáljon a Keys részhez.
- Kattintson az Add key => Create new key opcióra. Válassza a JSON kulcstípust és kattintson a Create gombra.
- Nyissa meg a letöltött JSON fájlt és másolja annak tartalmát, amelyet a Service account configuration string kapcsolódási paraméterként fog használni.
Kapcsolódás
- Navigáljon az alkalmazásokhoz és keressen rá a Google Vertex AI-ra. Ha nem találja a Google Vertex AI-t, kattintson a jobb felső sarokban található Add App gombra, válassza a Google Vertex AI-t és adja hozzá az alkalmazást a Blackbird környezetéhez.
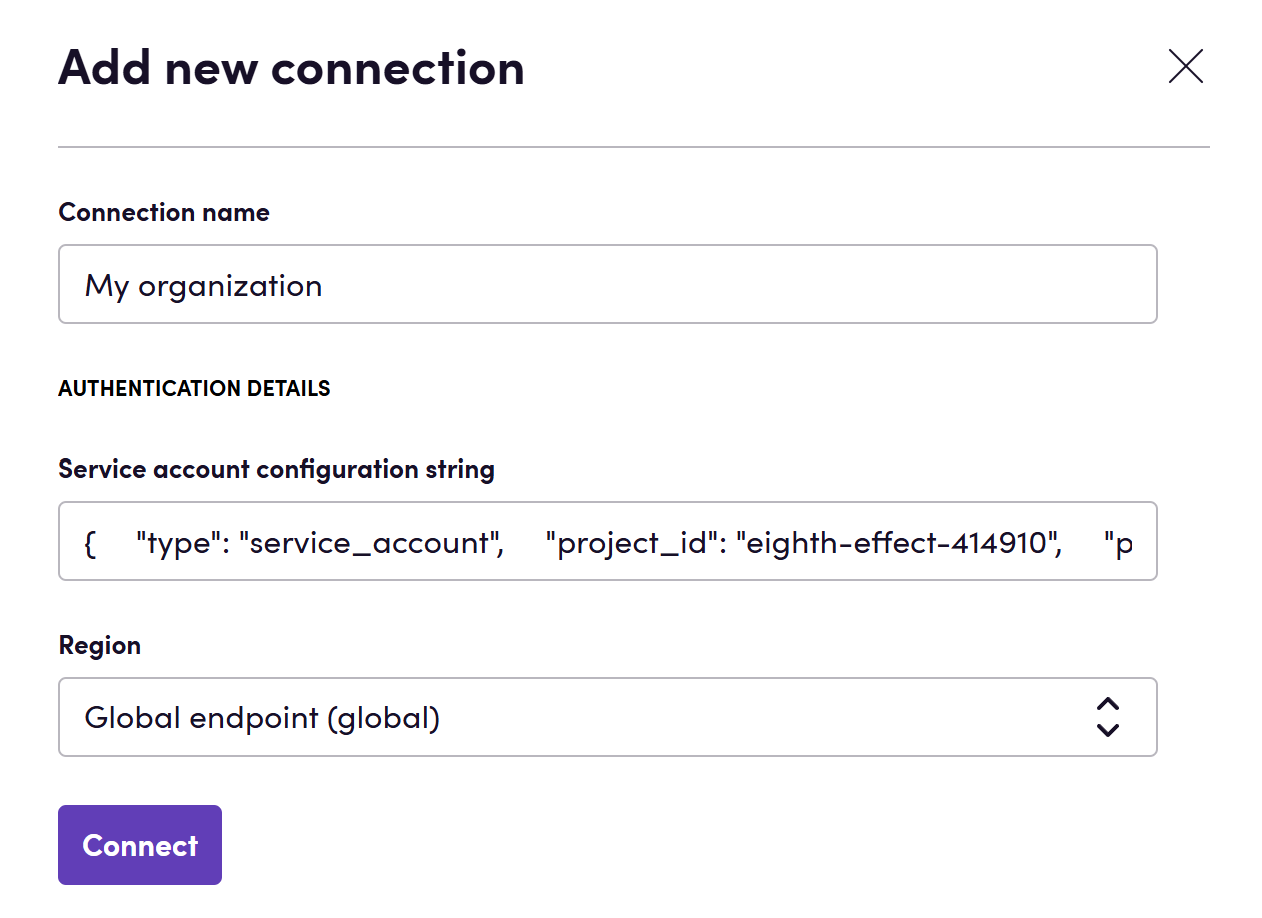
- Kattintson az Add Connection gombra.
- Nevezze el a kapcsolatot későbbi hivatkozáshoz, pl. ‘Saját szervezet’.
- Töltse ki a JSON konfigurációs karakterláncot, amelyet az előző lépésben szerzett.
- Kattintson a Connect gombra.
- Ellenőrizze, hogy a kapcsolat megjelent és a státusza Connected.
Megjegyzés: Jelenleg az alkalmazás a us-west1 helyen tárolt modellekkel működik. Ha más követelményei vannak, kérjük, tudassa velünk!
Actions
-
Generate text with Gemini szöveget generál a Gemini modell használatával. Ha a szöveggenerálás egyetlen prompton alapul, akkor a gemini-1.0-pro modellel kerül végrehajtásra. Opcionálisan megadhat egy képet vagy videót a gemini-1.0-pro-vision modellel történő generáláshoz. Mind a kép, mind a videó méretkorláta 20 MB. Ha már van kép, akkor videó nem adható meg és fordítva. A támogatott képformátumok a PNG és JPEG, míg a videóformátumok a MOV, MPEG, MP4, MPG, AVI, WMV, MPEGPS és FLV. Opcionálisan állítsa az Is Blackbird prompt értéket True-ra, jelezve, hogy az akciónak adott prompt az AI Utilities alkalmazás egyik akciójának eredménye. Megadhat biztonsági kategóriákat is a Safety categories bemeneti paraméterben és a hozzájuk tartozó küszöbértékeket a Thresholds for safety categories bemeneti paraméterben. Ha az egyik lista több elemet tartalmaz, mint a másik, a feleslegesek figyelmen kívül maradnak.
-
Get Quality Scores for XLIFF file XLIFF fájlokhoz szegmens- és fájlszintű minőségi pontszámokat ad. Opcionálisan hozzáadhatja a Threshold, New Target State és Condition bemeneti paramétereket a Blackbird művelethez, hogy megváltoztassa azon szegmensek célállapot-értékét, amelyek megfelelnek a kívánt feltételeknek (mindháromnak kitöltve kell lennie).
Opcionális bemenetek:
- Prompt: Adja meg a kritériumokat minden forrás-cél pár értékeléséhez. Ha nincs megadva, helyette az “accuracy, fluency, consistency, style, grammar and spelling” kerül használatra.
- Bucket size: Az ugyanabban a kérésben feldolgozandó fordítási egységek mennyisége. (Lásd a dedikált szekciót)
- Source and Target languages: Alapértelmezés szerint ezeket az értékeket az XLIFF fejlécből vesszük. Megadhat különböző értékeket, nincs szükség specifikus formátumra.
- Threshold: 0-10 közötti érték.
- Condition: Kritériumok azon szegmensek szűréséhez, amelyek célállapota módosításra kerül.
- New Target State: érték, amelyre a szűrt fordítási egységek célállapotát frissíti.
Kimenet:
- Average Score: az összes szegmensszintű pontszám összesített értéke.
- Updated XLIFF file: szegmensszintű pontszám hozzáadva az extradata attribútumhoz és frissített célállapot, ha utasítva lett.
-
Post-edit XLIFF file Frissíti az XLIFF fájl célszövegeit
Opcionális bemenetek:
- Prompt: Adja meg a nyelvészeti kritériumokat a célszövegek utószerkesztéséhez.
- Bucket size: Az ugyanabban a kérésben feldolgozandó fordítási egységek mennyisége. (Lásd a dedikált szekciót)
- Source and Target languages: Alapértelmezés szerint ezeket az értékeket az XLIFF fejlécből vesszük. Megadhat különböző értékeket, nincs szükség specifikus formátumra.
- Glossary
-
Process XLIFF file egy XLIFF fájl esetén feldolgozza az egyes fordítási egységeket a megadott utasítások szerint (alapértelmezés szerint lefordítja a forráscímkéket) és frissíti az egyes egységek célszövegét.
Megjegyzendő, hogy minden XLIFF művelet támogatja az XLIFF formátum 1.2-es és 2.1-es verzióit, mivel ezek a leggyakrabban használt verziók az iparágban. Ha más verziója van, kérjük, jelezze nekünk, és fontolóra vesszük a támogatás hozzáadását.
Bucket méret, teljesítmény és költség
Az XLIFF fájlok sok szegmenst tartalmazhatnak. Minden művelet veszi a szegmenseket és elküldi őket az AI alkalmazásnak feldolgozásra. Előfordulhat, hogy a szegmensek száma olyan magas, hogy a prompt meghaladja a modell kontextusablakát, vagy a modell hosszabb ideig tart, mint amennyi ideig a Blackbird műveleteknek megengedett. Ezért vezettük be a bucket méret paramétert. A bucket méret paraméter beállításával meghatározhatja, hány szegmenst küldjön egyszerre az AI modellnek. Ez lehetővé teszi a munkaterhelés felosztását különböző API-hívásokra. A kompromisszum az, hogy ugyanazt a kontextus promptot minden kéréssel el kell küldeni (ami növeli a felhasznált tokenek számát). Kísérleteink alapján azt találtuk, hogy 1500-as bucket méret elegendő az olyan modellekhez, mint a gpt-4o. Ezért 1500 az alapértelmezett bucket méret, azonban más modellek eltérő bucket méreteket igényelhetnek.
Visszajelzés
Szeretné használni ezt az alkalmazást, vagy visszajelzése van a megvalósításunkról? Lépjen kapcsolatba velünk a bevált csatornákon keresztül vagy hozzon létre egy problémát.