CMS Workflows - Contentful
A tartalomkezelő rendszerek (CMS) gyakran központi szerepet töltenek be a tartalmak kezelésében, amelyeknek lokalizációra vagy más típusú feldolgozásra lehet szükségük. Ha Blackbird-öt használ, valószínűleg integrálni szeretné egy CMS-sel. Ez az útmutató segít megérteni, hogyan építhet olyan munkafolyamatokat, amelyek a CMS-használat köré szerveződnek.
Bár az e-kereskedelmi platformokat vagy a termékinformáció-kezelő (PIM) rendszereket hivatalosan nem tekintik CMS-nek, sok hasonló funkciót kínálnak. Ennek eredményeként az ebben a dokumentumban található útmutatás ezekre a rendszerekre is vonatkozik.
Először megvizsgáljuk a CMS-ek közös jellemzőit és a lokalizációval kapcsolatos kihívásokat. Ezután a Contentful alkalmazást példaként használva, különböző stratégiákat mutatunk be a CMS lokalizációs munkafolyamatokra. Ezek a stratégiák bármely, a Blackbird-ön elérhető CMS alkalmazásra alkalmazhatók.
Kezdjük!
Az első dolog, amit meg kell kérdezned magadtól egy CMS munkafolyamat megközelítésekor, a következő:
Támogatja ez a CMS a lokalizációt?
Tapasztalataink szerint a válasz háromféle lehet:
- Igen (Contentful, Zendesk guides, Sitecore, Hubspot blog posts & pages, stb.)
- Igen, de csak egy népszerű bővítmény támogatásával (WordPress, Drupal, stb.)
- Nem (Marketo, Notion, Hubspot forms & emails, stb.)
Amikor a CMS a második vagy harmadik kategóriába tartozik, több “megoldástervezésre” lesz szükség a lehető legjobb munkafolyamat kialakításához. Látható, hogy néhány alkalmazás csak részben támogatja a natív lokalizációt (Hubspot), ez extra kihívásokat jelent, ha minden lehetséges tartalom lokalizálása a cél.
Ez az útmutató mostantól a három lehetőség közül az elsőre (és legegyszerűbbre) összpontosít. Későbbi útmutatók részletesebben foglalkoznak majd a többi lehetőséggel és megoldással, de arra építenek, ami itt le van írva.
1. Koncepciók
Egy tartalomkezelő rendszer általában (főként szöveges) tartalmat tárol, amely egy entitásba van csoportosítva. Ez az entitás rendszerfüggő. Példák entitásokra: cikk a Zendesk-ben, bejegyzés a Contentful-ban, termék a Shopify-ban vagy blogbejegyzés a WordPress-ben. De a WordPress-nek oldalai is vannak, és a Shopify-nak is vannak blogbejegyzései. Ez azt jelenti, hogy egy CMS különböző típusú lokalizálható entitásokkal is rendelkezhet.
Ami a tartalmat entitássá csoportosítja, azt általában úgy határozzák meg, mint “ami egy adott oldalon jelenik meg”. Ezért ezt az entitást szinonimának tekinthetjük a felhasználó által látható oldallal. Az oldalak és entitások bizonyos hierarchiával is rendelkeznek, amelyeket általában csoportokként vagy kategóriákként határoznak meg a CMS-ben. Ez megkönnyíti a különböző csoportokba vagy kategóriákba tartozó bejegyzések kezelését. Pl. “Le szeretném fordíttatni a GYIK kategóriába tartozó összes oldalt”.
Egy entitás tartalmaz tartalmat. Ez a tartalom egy nyelven íródott. Ezért az entitásnak rendelkeznie kell egy locale vagy nyelvi attribútummal (Megjegyzés: ez az, ami hiányzik azokból a CMS-ekből, amelyek nem támogatják natívan a lokalizációt). A nyelvi attribútum rendkívül fontos számunkra, mivel ez határozza meg leginkább, hogy melyik entitásból vesszük át a tartalmat, és melyik entitásba töltjük fel a fordításokat.
Végül, a CMS rendelkezhet olyan támogató funkciókkal is, amelyek kritikusak lehetnek a lokalizációs munkafolyamathoz, mint például a címkék vagy egyéni mezők.
Ezekkel a koncepciókkal felvértezve továbbléphetünk a következő részre: az alapvető fordítási munkafolyamat meghatározására.
2. Alapvető fordítási munkafolyamat
Alapvetően minden CMS-t érintő munkafolyamat a következő szerkezettel rendelkezik:
- Fordítandó tartalom lekérése.
- A tartalom feldolgozása (fordítása) a kívánt nyelvekre.
- A lefordított tartalom feltöltése a megfelelő entitás és nyelv kombinációra.
A CMS munkafolyamatok 3 P-je (Pull, Process, Push - lekérés, feldolgozás, feltöltés) mindig megjelenik a madaraidban.
Rajtad múlik, hogy meghozd a legfontosabb döntéseket, amelyek a 3 P-vel együtt alakítják a madaradat:
- ❓ Milyen tartalmat kell lekérni és mikor?
- ❓ Milyen nyelvekre kell fordítani?
- ❓ Melyik alkalmazás vagy szolgáltatás fogja feldolgozni a tartalmat?
Amikor döntöttél ezekről a szempontokról, látni fogod, hogy a Blackbird gondoskodik a többiről, nevezetesen:
- ✔️ Automatikusan átalakítja a tartalmat olyan HTML fájllá, amely pontosan reprezentálja az entitás tartalmát, így használható TMS kontextuson belüli fordításhoz vagy NMT feldolgozáshoz.
- ✔️ Nyelvi kódok megfeleltetése a különböző, a fájl feldolgozásához szükséges rendszerek között.
- ✔️ Várakozás hosszú feldolgozási lépésekre vagy emberi interakcióra (pl. várjon, amíg a fordító befejezi a fordítást).
- ✔️ Automatikusan feltölti a lefordított tartalmat a megfelelő entitás azonosítóhoz, ahogyan az a HTML fájlban be van ágyazva.
2.1 Gépi feldolgozás
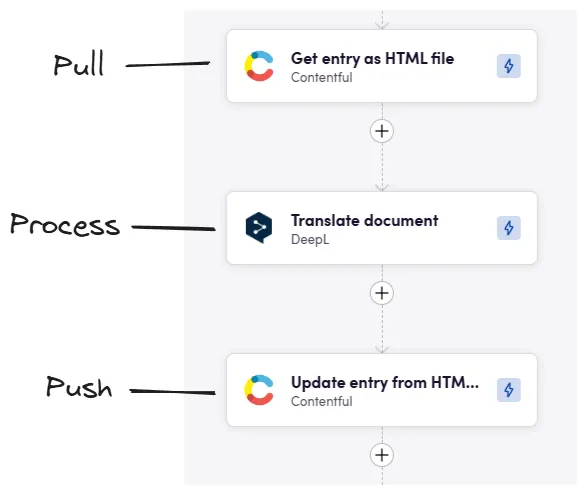
Vegyük ezt az elméleti munkafolyamatot és ültessük át a gyakorlatba. Az alábbi képen látható példa a lekérés, feldolgozás és feltöltés lépéseire a megfelelő műveletekkel a Contentfulban. A Get entry as HTML file műveletet használjuk a bejegyzést reprezentáló HTML fájl lekéréséhez. Ebben az esetben a DeepL-t használjuk a fájl feldolgozására (másik nyelvre fordítására). Végül az Update entry from HTML file műveletet használjuk arra, hogy a DeepL által lefordított HTML fájlt visszatöltsük a Contentfulba. Természetesen a DeepL helyettesíthető bármely más egylépéses feldolgozó alkalmazással, és ez a munkafolyamat hasonlóan nézne ki más CMS-ek esetében is.
2.2 Emberi beavatkozás az eljárásban
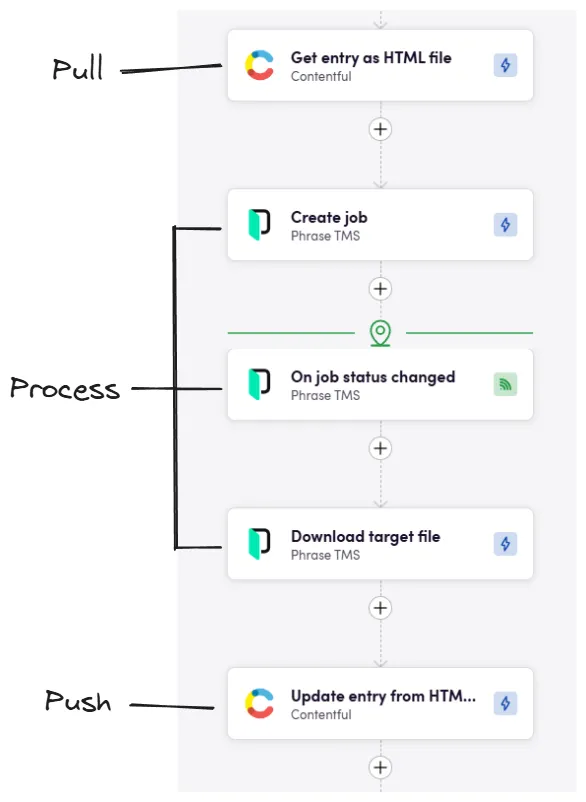
Valószínű, hogy a puszta gépi feldolgozás nem elégíti ki a lokalizációs igényeket. A fájl feldolgozása természetesen lehet többlépcsős folyamat. Ez szinte garantáltan így van, ha valamilyen emberi interakció vagy felügyelet is része a folyamatnak. Az alábbi példában a fájlt úgy dolgozzuk fel, hogy elküldjük egy Phrase TMS projektbe, és várunk, amíg a fordítás elkészül. Három lépést használunk a kívánt eredmény eléréséhez. Először létrehozunk egy új feladatot, majd várunk annak befejezésére egy ellenőrzőpont segítségével. Ezután letöltjük a lefordított fájlt a Phrase TMS-ből, mielőtt visszatöltenénk a Contentfulba. Bármilyen emberi beavatkozással történő folyamat bármely TMS vagy más releváns rendszer esetében hasonlóan néz ki.
💡 Megjegyzés: Nézd meg ellenőrzőpontok koncepció útmutatónkat hogy többet megtudj az ellenőrzőpontokról!
3. Folyamatos lokalizáció
Megtanultad, hogyan épül fel általában az alapvető fordítási munkafolyamat egy madárban. Itt az ideje, hogy foglalkozzunk az első három nagy döntés egyikével, amelyet magad tölthetsz ki: ❓ Milyen tartalmat kell lekérni és mikor?. Egy olyan felhasználási eset, amelyre a Blackbird nagyon alkalmas, a folyamatos lokalizáció. Röviden, a folyamatos lokalizációs folyamat akkor indítja el a lokalizációs munkafolyamatokat, amikor új tartalom jön létre. Ezt a megfelelő eseményindítóval érheted el a Blackbirdben!
A Contentful alapvető fordítási munkafolyamatunkhoz mindössze annyit kell tennünk, hogy létrehozunk egy eseményt, amely akkor indul, amikor új tartalom jön létre (vagy a mi esetünkben, amikor közzétesszük). Ezután a Get entry as HTML file műveletet az eseményből kapott bejegyzés azonosítóra irányítjuk.
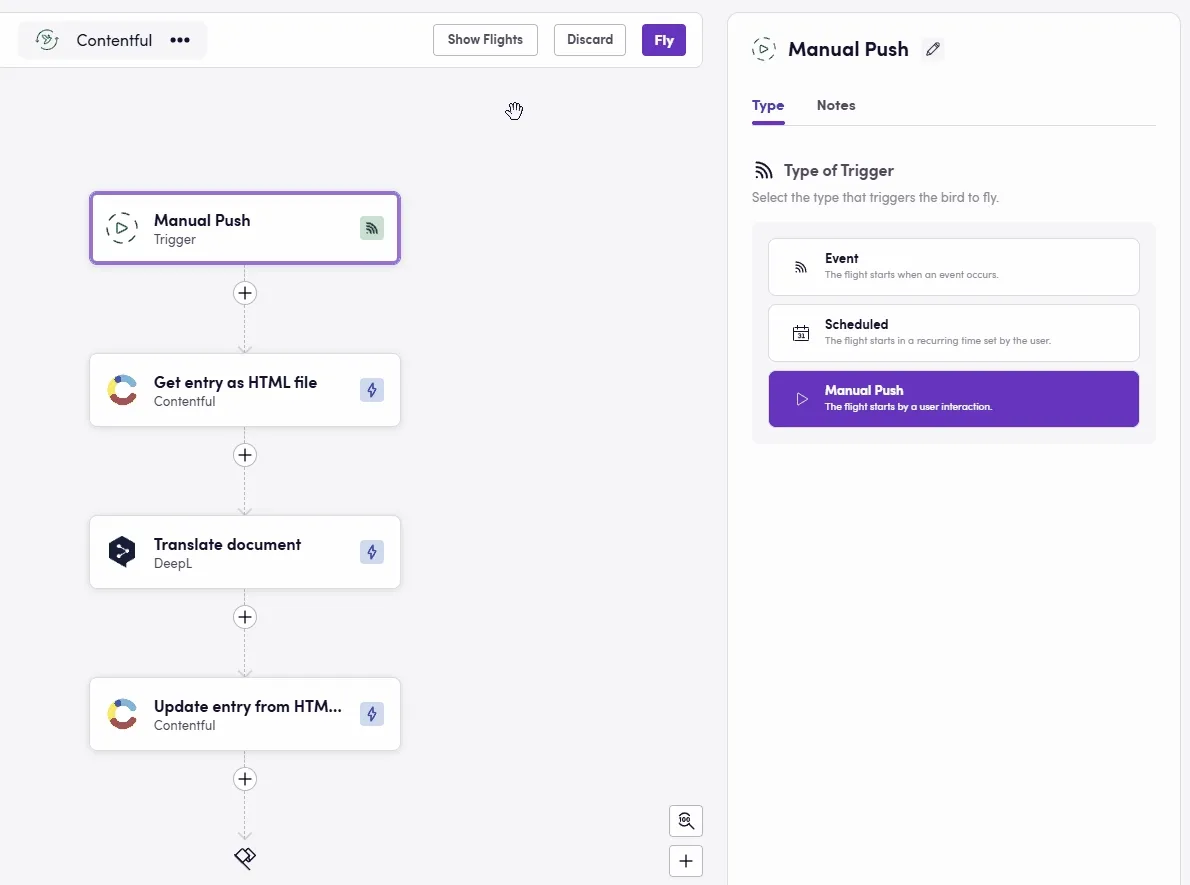
Ennyi! A folyamatos lokalizáció kipipálva. ✔️
A kritikus olvasó, a Contentful szakértő vagy mindkettő rámutatna egy kis hibára az imént létrehozott munkafolyamatban: amikor közzétesszük a lokalizált tartalmat, a munkafolyamat újra elindul, potenciálisan végtelen ciklust hozva létre. - Nos, le a kalappal előtted. Ez egy olyan probléma, amelyet különböző CMS-ekben különbözőképpen kezelnek. Például a Zendesk-ben szűrheted a közzétételi eseményt, hogy csak a forrásnyelvi közzétételeket figyelje. A Contentful azonban nem rendelkezik ilyen funkcióval, és minden közzététel elindítja ezt az eseményt.
Javasoljuk, hogy nézd meg a CMS-ek támogató funkcióit, mint a korábban említett címkék vagy egyéni mezők. Egy népszerű megoldás a Contentfulban a címkerendszer használata. A Blackbirdben szűrőket adhatsz hozzá a bejegyzési eseményekhez, hogy csak bizonyos címkével rendelkező bejegyzések indítsák el a madarat. Jó jelölt lehet például a Ready for localization (Lokalizációra kész). Ne felejtsd el törölni a címkét a munkafolyamat végén!
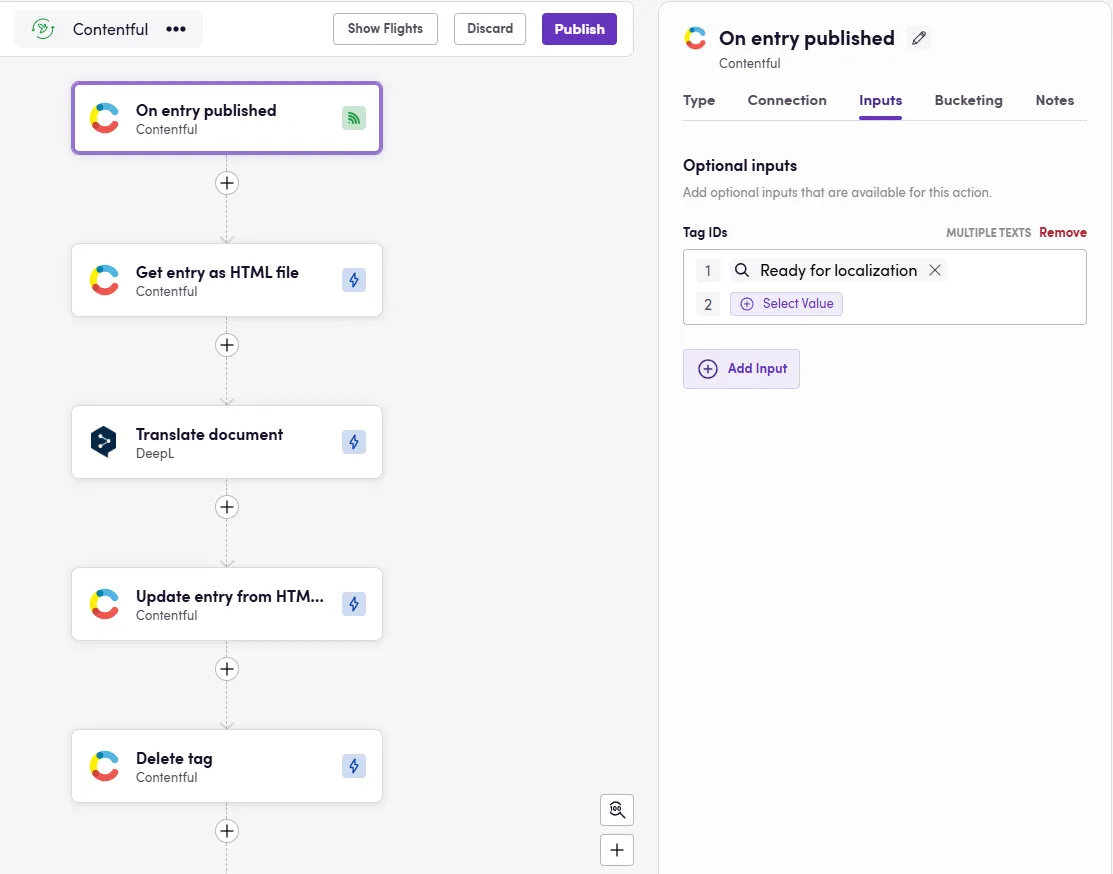
4. Ütemezett és történeti lokalizáció
Lehetséges, hogy a folyamatos lokalizáció nem egészen nyeri el a tetszésedet. Talán egy hagyományosabb lokalizációs munkafolyamat érdekel, ahol rendszeresen, például hetente egyszer veszel új fordítandó tartalmat. Vagy talán szeretnéd használni a folyamatos lokalizációt, de szükséged van a múltban közzétett entitások feldolgozására is. Mindkét esetben más megközelítést kell alkalmaznod a ❓ Milyen tartalmat kell lekérni és mikor? kérdésre. A mikor vagy egy ütemezett eseményindító, vagy egy manuális eseményindító lesz (amikor a ‘Fly’ gombra kattintasz a madaradban). A mit kérdést egy másik művelettel kell meghatároznod.
Minden CMS rendelkezik egy Search entities jellegű művelettel, amelyet arra használhatsz, hogy megkeresd és kiválaszd a pontosan feldolgozni kívánt tartalmat. Általában különböző szűrőkkel rendelkezik, beleértve az Updated from és Updated to szűrőket, amelyekkel kiválaszthatod azt az időtartományt, amelyben a tartalom frissíthető.
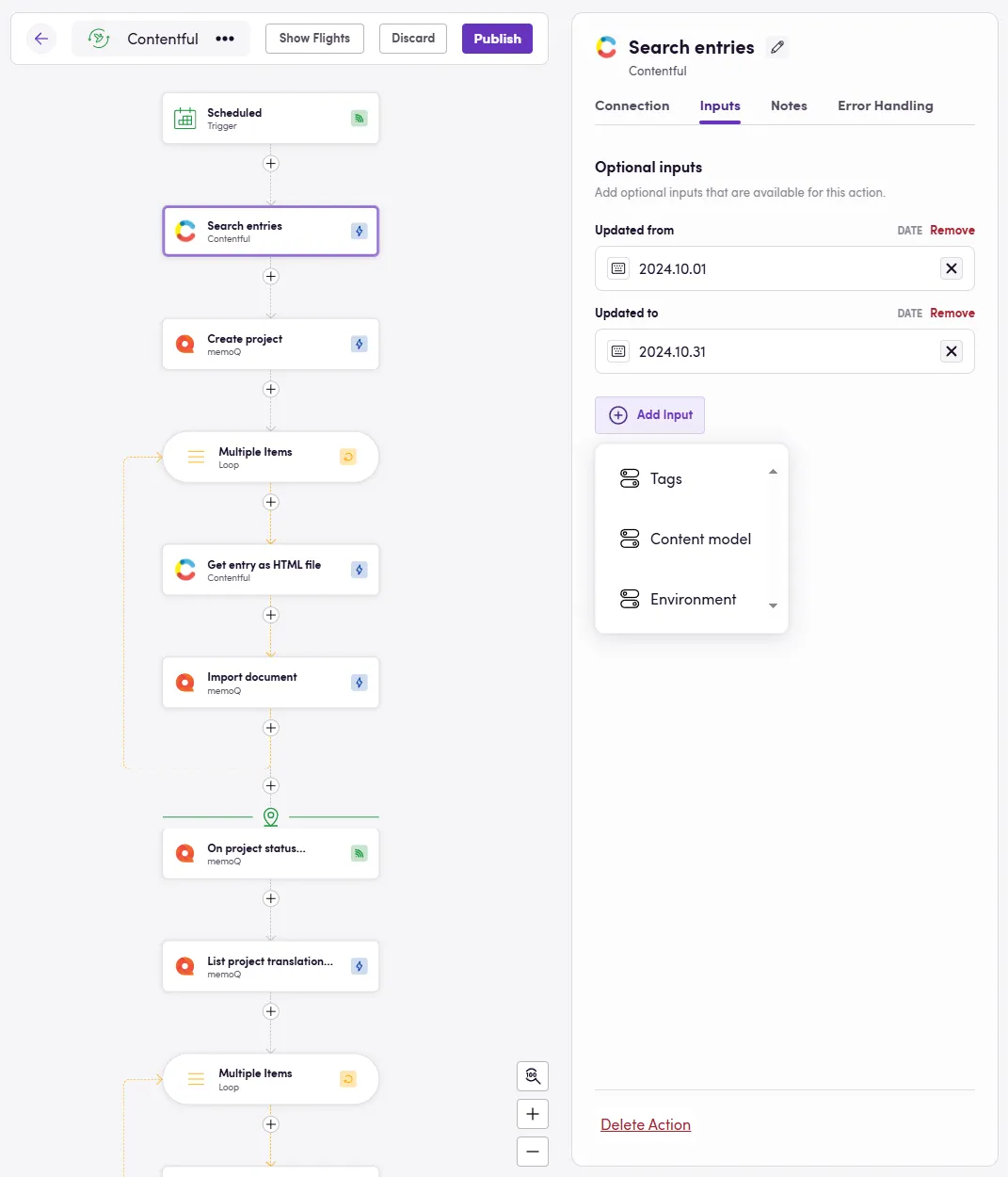
5. Több nyelv feldolgozása
Eddig minden madár, amit láttunk, csak egy nyelvre fordította a tartalmat. Azonban valószínűbb, hogy több nyelvre szeretnél fordítani. Ebben a részben tehát azzal a kérdéssel foglalkozunk, hogy ❓ Milyen nyelvekre kell fordítani?
A legegyszerűbb forgatókönyvben a nyelvek, amelyekre fordítani szeretnél, előre meghatározottak valamilyen megállapodás szerint. Általában “hardkódolhatod” ezeket a nyelveket azokba a műveletekbe, amelyeknek szükségük van rájuk. Az is valószínű, hogy okosan szeretnél eljár