Azure OpenAI
Azure OpenAI Service biedt toegang tot geavanceerde taalmodellen die u kunt aanpassen voor conversationele AI, het maken van content en datagrounding.
Voordat u begint
Voordat u verbinding kunt maken, moet u ervoor zorgen dat:
- U de
Resource URLvoor uw Azure OpenAI-account heeft. - U de
Deployment nameenAPI keyvoor uw Azure OpenAI-account weet.
Hier kunt u lezen hoe u een Azure OpenAI Service-resource kunt maken en implementeren hier.
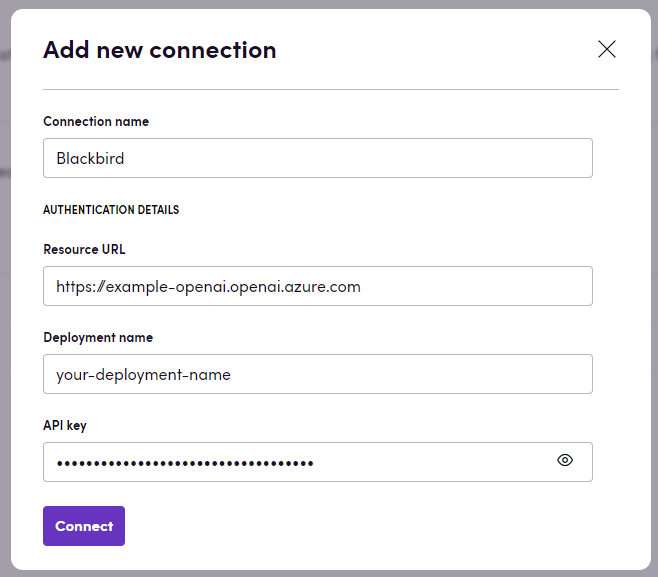
Verbinding maken
- Ga naar Apps en zoek de Azure OpenAI-app. U kunt de zoekfunctie gebruiken om deze te vinden.
- Klik op Add Connection.
- Geef uw verbinding een naam voor toekomstig gebruik, bijvoorbeeld ‘Mijn Azure OpenAI-verbinding’.
- Voer de
Resource URL,Deployment nameenAPI keyvoor uw Azure OpenAI-account in. - Klik op Connect.
- Controleer of de verbinding succesvol is toegevoegd.
LET OP: Let op uw
Resource URLverbindingsparameter. Soms kan de juiste URL een pad hebben na de domeinnaam. Bijvoorbeeld: https://example.openai.azure.com/**openai**
Actions
Chat actions
- Generate completion: Voltooit de gegeven prompt.
- Chat: Geeft een antwoord op basis van een chatbericht.
- Chat with system prompt: Geeft een antwoord op basis van een chatbericht en een configureerbare systeemprompt.
- Create summary: Vat de invoertekst samen.
- Generate edit: Bewerkt de invoertekst op basis van een instructieprompt.
- Execute Blackbird prompt: Voert prompt uit die gegenereerd is door Blackbird’s AI-hulpprogramma’s.
Translation-Related Actions
- Post-edit MT: Beoordeelt door MT vertaalde tekst en genereert een nagekeken versie.
- Get translation issues: Beoordeelt tekstvertaling en genereert een opmerking met de beschrijving van het probleem.
- Get MQM report: Voert een LQA-analyse van de vertaling uit. Het resultaat zal in het MQM-kader worden gepresenteerd.
- Get MQM dimension values: Voert een LQA-analyse van de vertaling uit. Deze actie geeft alleen de scores (tussen 1 en 10) van elke dimensie terug.
- Translate text: Lokaliseert de verstrekte tekst.
Audio Actions
- Create English translation: Genereert een vertaling naar het Engels op basis van een audio- of videobestand (mp3, mp4, mpeg, mpga, m4a, wav of webm).
- Create transcription: Genereert een transcriptie op basis van een audio- of videobestand (mp3, mp4, mpeg, mpga, m4a, wav of webm).
Image Actions
- Generate image: Genereert een afbeelding op basis van een prompt.
Text Analysis Actions
- Create embedding: Genereert een embedding voor een gegeven tekst. Een embedding is een lijst met floating-point getallen die semantische informatie vastlegt over de tekst die het vertegenwoordigt.
- Tokenize text: Tokeniseert de verstrekte tekst. Optioneel kunt u de codering specificeren: cl100k_base (gebruikt door gpt-4, gpt-3.5-turbo, text-embedding-ada-002) of p50k_base (gebruikt door codex-modellen, text-davinci-002, text-davinci-003).
XLIFF Actions
Let op: momenteel ondersteunt alleen gpt-4o versie: 2024-08-06 gestructureerde outputs. Dit betekent dat de acties die XLIFF-bestanden ondersteunen alleen kunnen worden gebruikt met deze modelversie. Relevante informatie over ondersteunde modellen vindt u in de Azure OpenAI-documentatie.
-
Get Quality Scores for XLIFF file Haalt segment- en bestandskwaliteitsscores op voor XLIFF-bestanden. Ondersteunt momenteel alleen versie 1.2 van XLIFF. Optioneel kunt u Threshold, New Target State en Condition invoerparameters toevoegen aan de Blackbird-actie om de doeltoestandswaarde van segmenten te wijzigen die aan de gewenste criteria voldoen (alle drie moeten worden ingevuld).
Optionele invoer:
- Prompt: Voeg uw criteria toe voor het scoren van elk bron-doelpaar. Als er geen criteria worden opgegeven, wordt dit vervangen door “accuracy, fluency, consistency, style, grammar and spelling”.
- Bucket size: Aantal vertaaleenheden die in dezelfde aanvraag worden verwerkt. (Zie speciale sectie)
- Source and Target languages: Standaard halen we deze waarden uit de XLIFF-header. U kunt verschillende waarden opgeven, er is geen specifieke notatie vereist.
- Threshold: waarde tussen 0-10.
- Condition: Criteria om segmenten te filteren waarvan de doeltoestand zal worden gewijzigd.
- New Target State: waarde om de doeltoestand bij te werken voor gefilterde vertaaleenheden.
Uitvoer:
- Average Score: geaggregeerde score van alle segmentscores.
- Updated XLIFF file: segmentscores toegevoegd aan extradata-attribuut & bijgewerkte doeltoestand indien geïnstrueerd.
-
Post-edit XLIFF file Werkt de doelen van XLIFF 1.2-bestanden bij
Optionele invoer:
- Prompt: Voeg uw taalkundige criteria toe voor het nabewerken van doelen.
- Bucket size: Aantal vertaaleenheden die in dezelfde aanvraag worden verwerkt. (Zie speciale sectie)
- Source and Target languages: Standaard halen we deze waarden uit de XLIFF-header. U kunt verschillende waarden opgeven, er is geen specifieke notatie vereist.
- Glossary
-
Process XLIFF file verwerkt, gegeven een XLIFF-bestand, elke vertaaleenheid volgens de verstrekte instructies (standaard is het vertalen van brontags) en werkt de doeltekst voor elke eenheid bij. Deze actie ondersteunt momenteel alleen versie 1.2 van XLIFF.
Bucket size, prestaties en kosten
XLIFF-bestanden kunnen veel segmenten bevatten. Elke actie neemt uw segmenten en stuurt ze naar de AI-app voor verwerking. Het is mogelijk dat het aantal segmenten zo hoog is dat de prompt het contextvenster van het model overschrijdt of dat het model langer duurt dan Blackbird-acties mogen duren. Daarom hebben we de bucket size-parameter geïntroduceerd. U kunt de bucket size-parameter aanpassen om te bepalen hoeveel segmenten tegelijk naar het AI-model worden gestuurd. Hiermee kunt u de werklast opdelen in verschillende API-oproepen. Het nadeel is dat dezelfde contextprompt met elke aanvraag moet worden meegestuurd (wat de gebruikte tokens verhoogt). Uit experimenten is gebleken dat een bucket size van 1500 voldoende is voor modellen zoals gpt-4o. Daarom is 1500 de standaard bucket size, maar andere modellen kunnen andere bucket sizes vereisen.
Batchverwerking
U kunt batch (async) acties gebruiken om grote XLIFF-bestanden te verwerken. De batchactie geeft een batch-object terug dat u kunt gebruiken om de status van de verwerking te controleren met behulp van de Batch ID. Merk op dat het model moet worden geïmplementeerd als Global-batch. Voor meer informatie over het implementeren van een model als Global-batch, raadpleegt u de Azure OpenAI-documentatie.
We gebruiken de Deployment name (uit de verbinding) als het model, dus u moet ervoor zorgen dat het model is geïmplementeerd als Global-batch en dat u de juiste implementatienaam in de verbinding heeft opgegeven. Een voorbeeld van een implementatienaam is: organization-gpt-4o-globalbatch.
- (Batch) Process XLIFF file - Verwerkt asynchroon elke vertaaleenheid in het XLIFF-bestand volgens de verstrekte instructies (standaard vertaalt het gewoon de brontags) en werkt de doeltekst voor elke eenheid bij.
- (Batch) Post-edit XLIFF file - Werkt asynchroon de doeltekst van elke vertaaleenheid in het XLIFF-bestand na volgens de verstrekte instructies en werkt de doeltekst voor elke eenheid bij.
- (Batch) Get Quality Scores for XLIFF file - Haalt asynchroon kwaliteitsscores op voor elke vertaaleenheid in het XLIFF-bestand.
Om de resultaten van de batchverwerking te krijgen, kunt u de volgende acties gebruiken:
- (Batch) Get results of the batch process - Haalt de resultaten van het batchproces op. Deze actie is alleen geschikt voor het verwerken en nabewerken van XLIFF-bestanden en moet worden aangeroepen nadat het batchproces is voltooid.
- (Batch) Get quality scores results - Haalt de kwaliteitsscoreresultaten van het batchproces op. Deze actie is alleen geschikt voor het ophalen van kwaliteitsscores voor XLIFF-bestanden en moet worden aangeroepen nadat het batchproces is voltooid.
Let op dat u het juiste originele XLIFF-bestand moet specificeren in de Original XLIFF-invoer. Dit helpt ons om het juiste XLIFF-bestand te construeren met bijgewerkte doelsegmenten.
Voorbeeld
Hier is een voorbeeld van hoe u de Azure OpenAI-app in een workflow kunt gebruiken:
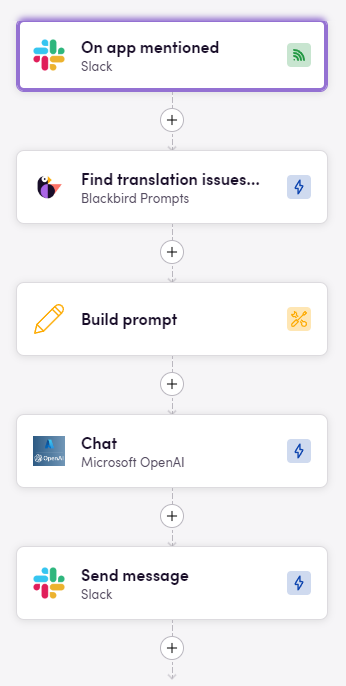
Deze workflow automatiseert het proces van het afhandelen van een specifieke trigger in Slack. Hier is een stapsgewijze uitleg:
- On app mentioned (Slack): De workflow start wanneer de app wordt genoemd in een Slack-kanaal.
- Find translation issues (Blackbird Prompts): Vervolgens gebruikt het Blackbird Prompts om vertaalproblemen in de genoemde inhoud te vinden.
- Build prompt: Vervolgens wordt een prompt gebouwd op basis van de geïdentificeerde problemen.
- Chat (Azure OpenAI): De opgebouwde prompt wordt naar Azure OpenAI gestuurd om een antwoord of oplossing te genereren.
- Send message (Slack): Ten slotte wordt het antwoord van OpenAI teruggestuurd als een bericht in het Slack-kanaal.
Feedback
Wilt u deze app gebruiken of heeft u feedback op onze implementatie? Neem contact met ons op via de bekende kanalen of maak een issue aan.