Google Vertex AI
Vertex AI is een uitgebreid platform dat toegang biedt tot krachtige multimodale modellen zoals Gemini van Google, waarmee ontwikkelaars naadloos verschillende inputs zoals tekst, afbeeldingen, video of code kunnen combineren. Met een diverse selectie aan modellen vergemakkelijkt Vertex AI eenvoudige aanpassing en integratie, waardoor de ontwikkeling en implementatie van AI-toepassingen mogelijk wordt. Het platform biedt generatieve AI-modellen, volledig beheerde tools en doelgerichte MLOps-oplossingen om de volledige machine learning-levenscyclus te stroomlijnen—van training en afstemming tot implementatie en monitoring.
Voordat je begint
Voordat je verbinding kunt maken, moet je ervoor zorgen dat:
- Je een Cloud Platform-project hebt geselecteerd of aangemaakt.
- Je facturering hebt ingeschakeld voor je project.
- Je de Vertex AI API hebt ingeschakeld.
- Je een serviceaccount hebt aangemaakt en JSON-sleutels hebt gegenereerd.
Serviceaccount aanmaken en JSON-sleutels genereren
- Navigeer naar het geselecteerde of aangemaakte Cloud Platform-project.
- Ga naar de sectie IAM & Admin.
- Selecteer in de linker zijbalk Service accounts.
- Klik op Create service account.
- Voer een naam voor het serviceaccount in en optioneel een beschrijving. Klik op Create and continue. Selecteer de rol Vertex AI Administrator of Vertex AI User voor het serviceaccount en klik op Continue.
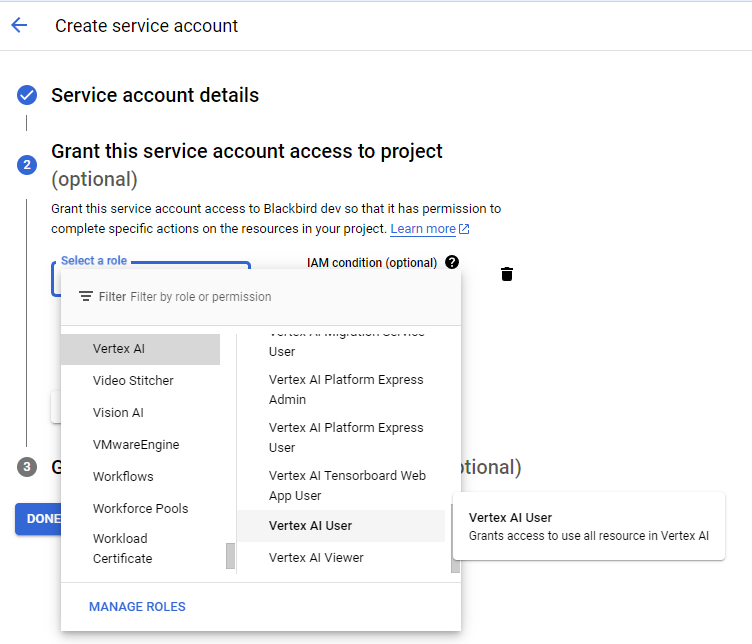
- Klik op Done.
- Selecteer in de lijst met serviceaccounts het nieuw aangemaakte serviceaccount en navigeer naar de sectie Keys.
- Klik op Add key => Create new key. Kies het sleuteltype JSON en klik op Create.
- Open het gedownloade JSON-bestand en kopieer de inhoud, die zal worden gebruikt in de verbindingsparameter Service account configuration string.
Verbinden
- Navigeer naar apps en zoek naar Google Vertex AI. Als je Google Vertex AI niet kunt vinden, klik dan op Add App in de rechterbovenhoek, selecteer Google Vertex AI en voeg de app toe aan je Blackbird-omgeving.
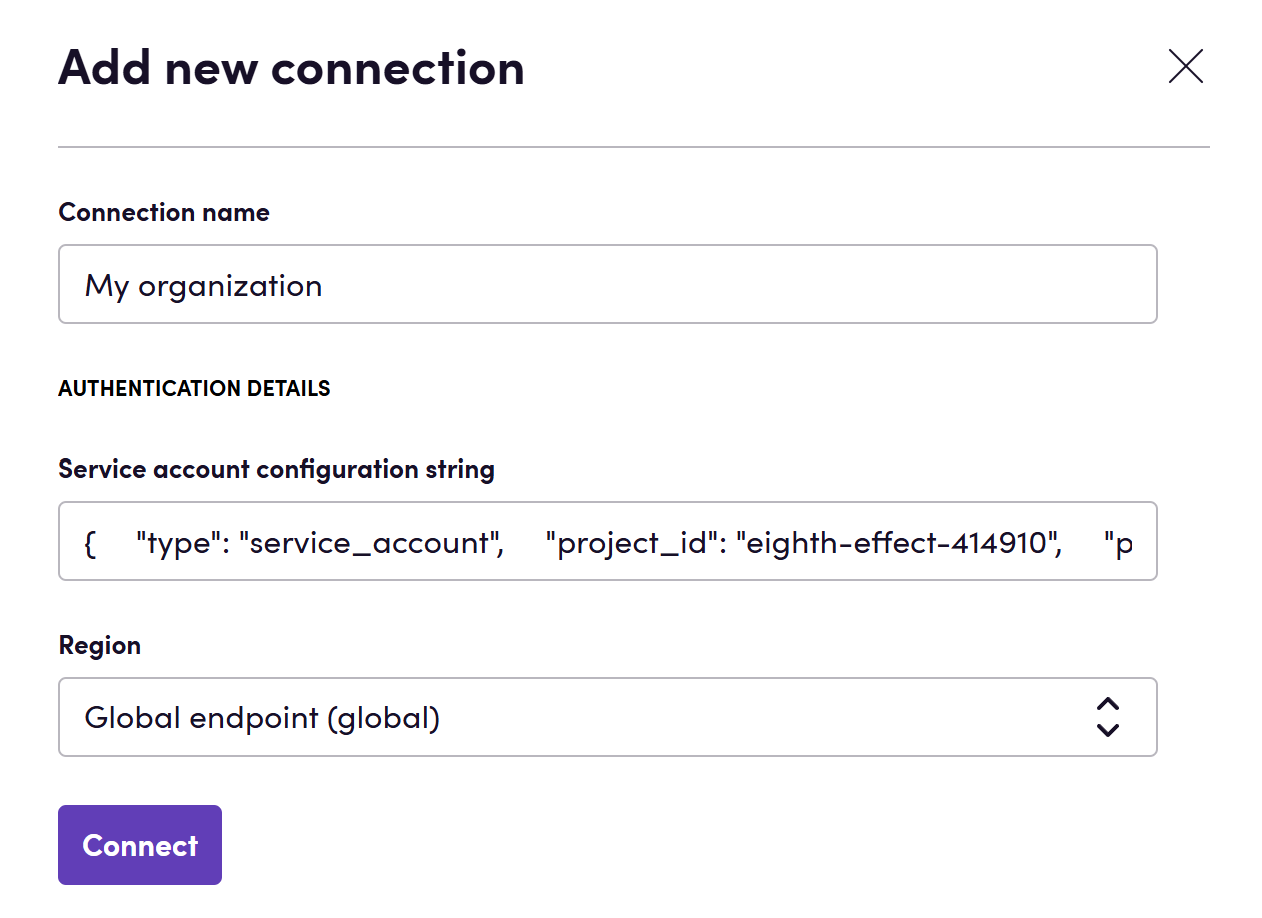
- Klik op Add Connection.
- Geef je verbinding een naam voor toekomstige referentie, bijv. ‘Mijn organisatie’.
- Vul de JSON-configuratiestring in die je in de vorige stap hebt verkregen.
- Klik op Connect.
- Controleer of de verbinding is verschenen en de status Connected is.
Opmerking: Momenteel werkt de app voor modellen die zijn opgeslagen op de locatie us-west1. Als je andere vereisten hebt, laat het ons dan weten!
Actions
-
Generate text with Gemini genereert tekst met behulp van het Gemini-model. Als tekstgeneratie is gebaseerd op een enkele prompt, wordt deze uitgevoerd met het gemini-1.0-pro model. Optioneel kun je een afbeelding of video specificeren om generatie uit te voeren met het gemini-1.0-pro-vision model. Zowel afbeelding als video hebben een groottelimiet van 20 MB. Als er al een afbeelding aanwezig is, kan video niet worden gespecificeerd en vice versa. Ondersteunde afbeeldingsformaten zijn PNG en JPEG, terwijl videoformaten MOV, MPEG, MP4, MPG, AVI, WMV, MPEGPS en FLV omvatten. Optioneel, stel Is Blackbird prompt in op True om aan te geven dat de prompt die aan de actie is gegeven het resultaat is van een van de acties van de AI Utilities-app. Je kunt ook veiligheidscategorieën specificeren in de invoerparameter Safety categories en respectieve drempels voor hen in de invoerparameter Thresholds for safety categories. Als één lijst meer items heeft dan de andere, worden extra items genegeerd.
-
Get Quality Scores for XLIFF file Krijgt segment- en bestandsniveaukwaliteitsscores voor XLIFF-bestanden. Optioneel kun je de invoerparameters Threshold, New Target State en Condition toevoegen aan de Blackbird-actie om de doelstaatwaarde van segmenten te wijzigen die aan de gewenste criteria voldoen (alle drie moeten worden ingevuld).
Optionele invoer:
- Prompt: Voeg je criteria toe voor het scoren van elk bron-doelpaar. Als er geen worden opgegeven, wordt dit vervangen door “accuracy, fluency, consistency, style, grammar and spelling”.
- Bucket size: Aantal vertaaleenheden om in dezelfde aanvraag te verwerken. (Zie toegewijde sectie)
- Source and Target languages: Standaard halen we deze waarden uit de XLIFF-header. Je kunt verschillende waarden opgeven, geen specifiek formaat vereist.
- Threshold: waarde tussen 0-10.
- Condition: Criteria om segmenten te filteren waarvan de doelstaat zal worden gewijzigd.
- New Target State: waarde om de doelstaat naar te updaten voor gefilterde vertaaleenheden.
Uitvoer:
- Average Score: geaggregeerde score van alle segmentniveauscores.
- Updated XLIFF file: segmentniveauscore toegevoegd aan extradata-attribuut & bijgewerkte doelstaat indien opgedragen.
-
Post-edit XLIFF file Werkt de doelen van XLIFF-bestand bij
Optionele invoer:
- Prompt: Voeg je taalkundige criteria toe voor het bewerken van doelen.
- Bucket size: Aantal vertaaleenheden om in dezelfde aanvraag te verwerken. (Zie toegewijde sectie)
- Source and Target languages: Standaard halen we deze waarden uit de XLIFF-header. Je kunt verschillende waarden opgeven, geen specifiek formaat vereist.
- Glossary
-
Process XLIFF file gegeven een XLIFF-bestand, verwerkt elke vertaaleenheid volgens de verstrekte instructies (standaard is het vertalen van brontags) en werkt de doeltekst voor elke eenheid bij.
Merk op dat alle XLIFF-acties de versies 1.2 en 2.1 van het XLIFF-formaat ondersteunen, aangezien deze versies het meest worden gebruikt in de industrie. Als je een andere versie hebt, laat het ons dan weten en we zullen overwegen om ondersteuning ervoor toe te voegen.
Bucket size, prestaties en kosten
XLIFF-bestanden kunnen veel segmenten bevatten. Elke actie neemt je segmenten en stuurt ze naar de AI-app voor verwerking. Het is mogelijk dat het aantal segmenten zo hoog is dat de prompt het contextvenster van het model overschrijdt of dat het model langer duurt dan Blackbird-acties mogen duren. Daarom hebben we de parameter bucket size geïntroduceerd. Je kunt de parameter bucket size aanpassen om te bepalen hoeveel segmenten tegelijk naar het AI-model worden gestuurd. Hiermee kun je de werklast verdelen over verschillende API-aanroepen. De afweging is dat dezelfde contextprompt met elke aanvraag moet worden meegestuurd (wat de gebruikte tokens verhoogt). Uit experimenten hebben we ontdekt dat een bucket size van 1500 voldoende is voor modellen zoals gpt-4o. Daarom is 1500 de standaard bucket size, maar andere modellen kunnen verschillende bucket sizes vereisen.
Feedback
Wil je deze app gebruiken of heb je feedback op onze implementatie? Neem contact met ons op via de gevestigde kanalen of maak een issue aan.