Hugging Face
Hugging Face is een platform dat tools biedt voor het bouwen, trainen en implementeren van machine learning-modellen. Het biedt een uitgebreide verzameling vooraf getrainde modellen en gebruiksvriendelijke tools, waardoor ontwikkelaars en onderzoekers efficiënt geavanceerde ML-modellen kunnen creëren en optimaliseren voor verschillende taken, met name op het gebied van natuurlijke taalverwerking.
Voordat je begint
Voordat je verbinding kunt maken, moet je:
- Een Hugging Face account aanmaken.
- Een Toegangstoken verkrijgen:
- Klik op New token.
- Voer een Name in voor het token en selecteer de Role uit de dropdown.
- Klik op de knop Generate a token.
- Klik naast het gegenereerde token op het pictogram Copy token to clipboard.
Een model trainen of finetunen met aangepaste gegevens
Hugging Face biedt een tool voor het trainen van ML-modellen die kan worden gebruikt om beter aan je behoeften te voldoen. Je kunt meer lezen over AutoTrain hier. Zodra het model is getraind op jouw gegevens, kun je het via Blackbird gebruiken zoals elk ander model.
Verbinding maken
- Navigeer naar apps en zoek naar Hugging Face. Als je Hugging Face niet kunt vinden, klik dan op Add App in de rechterbovenhoek, selecteer Hugging Face en voeg de app toe aan je Blackbird-omgeving.
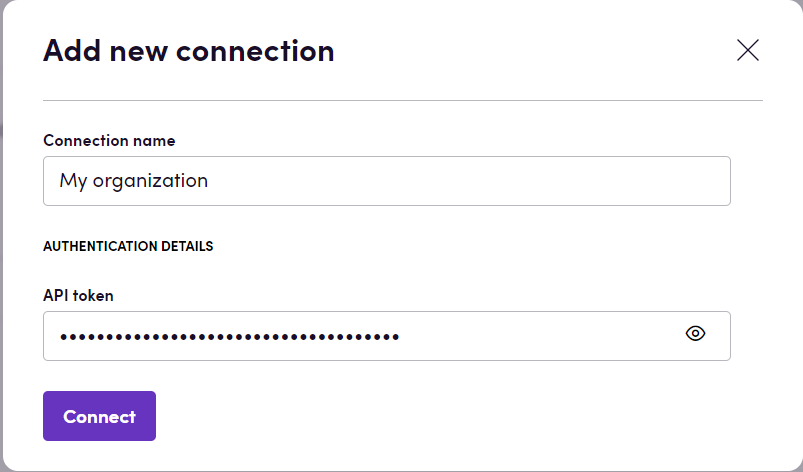
- Klik op Add Connection.
- Geef je verbinding een naam voor toekomstig gebruik, bijvoorbeeld ‘Mijn organisatie’.
- Vul het API-token in dat je in de vorige sectie hebt verkregen.
- Klik op Connect.
- Controleer of de verbinding is verschenen en de status Connected is.
Actions
Text
- Summarize text vat langere tekst samen tot kortere tekst.
- Answer question beantwoordt de vraag op basis van een context. Context is een tekst waarin het antwoord gevonden kan worden.
- Answer question with table beantwoordt de vraag op basis van een Excel-tabel met .xlsx-extensie waarin het antwoord gevonden kan worden.
- Classify text voert tekstclassificatie uit. Mogelijke labels variëren afhankelijk van het gebruikte model. Kan nuttig zijn voor sentimentanalyse.
- Classify text according to candidate labels voert tekstclassificatie uit en, in tegenstelling tot de actie Classify text, gebruikt het de opgegeven labels voor voorspelling.
- Translate text. Bron- en doeltaal kunnen niet worden gespecificeerd. Het wordt aanbevolen om modellen te gebruiken die zijn getraind om tussen één talenpaar te vertalen. Kijk bijvoorbeeld naar Helsinki-NLP modellen.
- Fill mask vult een gat of gaten met ontbrekende woorden en retourneert tekst met gevulde gaten. Gebruik het maskertoken om de plaats aan te geven die moet worden ingevuld. Het maskertoken kan verschillen afhankelijk van het gebruikte model, maar de meest gebruikte tokens zijn [MASK] of <mask>. Je moet het maskertoken dat door een specifiek model wordt gebruikt controleren op de Hugging Face-pagina.
- Calculate semantic similarity berekent semantische overeenkomst tussen twee teksten en geeft een overeenkomstscore in het bereik van 0 tot 1.
- Generate text vervolgt tekst vanuit een prompt.
- Chat voert conversationele taken uit. Om context te geven, kun je eerdere gebruikersinvoer en eerder gegenereerde antwoorden opgeven, die dezelfde lengte moeten hebben.
- Classify tokens voert tokenclassificatie uit. Wordt meestal gebruikt voor het extraheren van trefwoorden of grammaticale zinsontleding. Je kunt modelgebruik en entiteitsgroepen (tags) controleren op de betreffende Hugging Face-pagina van het model.
- Generate embedding genereert tekstembedding - een lijst met floating point-getallen die semantische informatie vastlegt over de tekst die het vertegenwoordigt. Embeddings kunnen worden gebruikt om gegevens op te slaan in vectordatabases (zoals Pinecone).
Audio
- Create transcription genereert een transcriptie van een audiobestand (Flac, Wav, Mp3, Ogg etc.).
- Classify audio voert audioclassificatie uit. Mogelijke labels variëren afhankelijk van het gebruikte model.
Image
- Generate image genereert een afbeelding op basis van een tekstbeschrijving van de afbeelding.
- Classify image voert beeldclassificatie uit. Mogelijke labels variëren afhankelijk van het gebruikte model.
- Convert image to text genereert een tekstbeschrijving voor een gegeven afbeelding.
- Answer question based on image voert visuele vraagbeantwoording uit op basis van een gegeven afbeelding.
Opmerking: veel acties hebben een optionele invoerparameter Use cache. Standaard is deze ingesteld op true, wat betekent dat als het model dezelfde invoer al eerder heeft gezien, het het eerder verkregen resultaat zal teruggeven. Je kunt dit gebruiken om ervoor te zorgen dat je deterministische resultaten krijgt. Als je niet wilt dat het model exact dezelfde resultaten teruggeeft voor query’s die het eerder heeft gezien, kun je Use cache instellen op false.
Ontbrekende functies
In de toekomst kunnen we acties toevoegen voor:
- Beelddetectie
- Beeldsegmentatie
Laat het ons weten als je hierin geïnteresseerd bent!