Hugging Face
Hugging Face - це платформа, яка надає інструменти для створення, навчання та розгортання моделей машинного навчання. Вона пропонує багатий репозиторій попередньо навчених моделей та зручні інструменти, що дозволяють розробникам та дослідникам ефективно створювати та оптимізувати сучасні моделі машинного навчання для різних завдань, особливо у сфері обробки природної мови.
Перед налаштуванням
Перед підключенням вам потрібно:
- Створити обліковий запис Hugging Face.
- Отримати Токен доступу:
- Натисніть New token.
- Введіть Name (Назву) для токена та виберіть Role (Роль) з випадаючого списку.
- Натисніть кнопку Generate a token.
- Поруч зі згенерованим токеном натисніть на значок Copy token to clipboard.
Тренування або дооптимізація моделі з використанням власних даних
Hugging Face надає інструмент для навчання моделей машинного навчання, який можна використовувати для кращого задоволення ваших потреб. Ви можете дізнатися більше про AutoTrain тут. Після навчання моделі на ваших даних, ви можете використовувати її через Blackbird так само, як і будь-яку іншу модель.
Підключення
- Перейдіть до додатків і знайдіть Hugging Face. Якщо ви не можете знайти Hugging Face, натисніть Add App у верхньому правому куті, виберіть Hugging Face і додайте додаток до вашого середовища Blackbird.
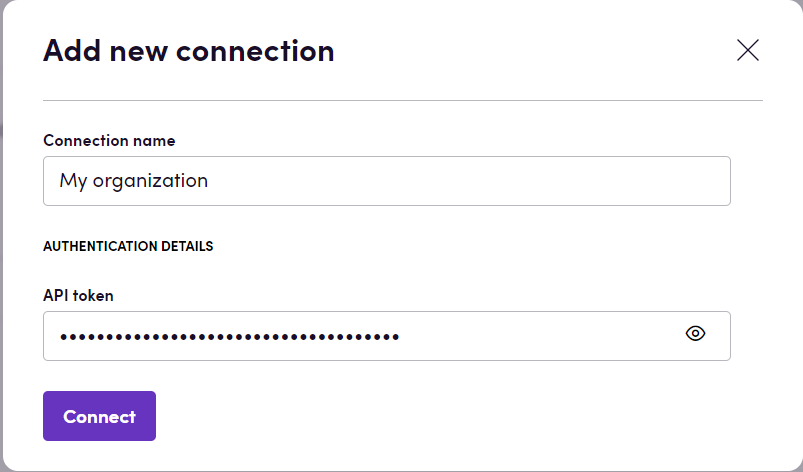
- Натисніть Add Connection.
- Назвіть ваше підключення для подальшого використання, наприклад, ‘Моя організація’.
- Введіть API токен, отриманий у попередньому розділі.
- Натисніть Connect.
- Переконайтеся, що підключення з’явилося і статус Connected.
Actions
Text
- Summarize text узагальнює довший текст у коротший.
- Answer question відповідає на запитання на основі наданого контексту. Контекст - це текст, у якому можна знайти відповідь.
- Answer question with table відповідає на запитання на основі таблиці Excel з розширенням .xlsx, у якій можна знайти відповідь.
- Classify text виконує класифікацію тексту. Можливі мітки залежать від використовуваної моделі. Може бути корисним для аналізу настроїв.
- Classify text according to candidate labels виконує класифікацію тексту і, на відміну від дії Classify text, використовує надані мітки для прогнозування.
- Translate text. Вихідну та цільову мову не можна вказати. Рекомендується використовувати моделі, навчені для перекладу між однією мовною парою. Наприклад, подивіться на моделі Helsinki-NLP.
- Fill mask заповнює пропуски або отвори відсутніми словами і повертає текст із заповненими пропусками. Використовуйте токен маски, щоб вказати місце для заповнення. Токен маски може відрізнятися залежно від використовуваної моделі, але найчастіше використовуються токени [MASK] або <mask>. Перевірте токен маски, який використовується конкретною моделлю на її сторінці Hugging Face.
- Calculate semantic similarity обчислює семантичну подібність між двома текстами і повертає оцінку подібності в діапазоні від 0 до 1.
- Generate text продовжує текст з підказки.
- Chat виконує розмовне завдання. Щоб надати контекст, ви можете вказати минулі введення користувача та раніше згенеровані відповіді, які повинні мати однакову довжину.
- Classify tokens виконує класифікацію токенів. Зазвичай використовується для витягання ключових слів або граматичного аналізу речення. Ви можете перевірити використання моделі та групи сутностей (теги) на відповідній сторінці моделі в Hugging Face.
- Generate embedding генерує вкладення тексту - список чисел з плаваючою комою, який фіксує семантичну інформацію про текст, який він представляє. Вкладення можна використовувати для зберігання даних у векторних базах даних (як-от Pinecone).
Audio
- Create transcription створює транскрипцію на основі аудіофайлу (Flac, Wav, Mp3, Ogg тощо).
- Classify audio виконує класифікацію аудіо. Можливі мітки залежать від використовуваної моделі.
Image
- Generate image генерує зображення на основі текстового опису зображення.
- Classify image виконує класифікацію зображень. Можливі мітки залежать від використовуваної моделі.
- Convert image to text генерує текстовий опис для даного зображення.
- Answer question based on image надає відповіді на візуальні запитання на основі даного зображення.
Примітка: багато дій мають необов’язковий вхідний параметр Use cache. За замовчуванням він встановлений на true, що означає, що якщо модель вже бачила такий самий ввід, вона поверне раніше отриманий результат. Ви можете використовувати це, щоб гарантувати отримання детермінованих результатів. Якщо ви не хочете, щоб модель повертала точно такі ж результати для запитів, які вона бачила раніше, ви можете встановити Use cache на false.
Відсутні функції
У майбутньому ми можемо додати дії для:
- Розпізнавання зображень
- Сегментації зображень
Повідомте нам, якщо ви зацікавлені!